
ウェブサイト運営において、AI、特に生成AIの役割が急速に拡大しています。ユーザーが情報を得る方法が変化する中で、自社のウェブサイトがAIにどのように認識され、活用されるかは、今後のオンラインでの成功を左右する重要な要素です。その鍵を握る一つが、ウェブサイトの「交通整理役」ともいえるrobots.txtファイルです。この記事では、なぜ今robots.txtでAIボットへのアクセス許可が重要なのか、そして具体的にどのように設定すれば良いのかを、分かりやすく解説します。
robots.txtとは?基本をおさらい
robots.txt(ロボッツ・ティーエックスティーと読みます)は、ウェブサイトのルートディレクトリ(例:https://example.com/robots.txt)に設置するテキストファイルです。このファイルの主な役割は、検索エンジンなどの「クローラー」と呼ばれる情報収集ロボットに対して、ウェブサイト内のどのページをクロール(訪問・情報収集)して良いか、またはどのページをクロールしないでほしいかを伝えることです。これにより、ウェブサイト運営者は、機密情報が含まれるページや、検索結果に表示させたくないページへのアクセスを制御できます。また、無駄なクロールを防ぐことで、サーバーへの負荷を軽減する効果も期待できます。非常にシンプルな記述ルールで構成されていますが、ウェブサイトの見つけやすさや、情報の扱われ方に大きな影響を与える重要なファイルです。
なぜAIボットのアクセス許可がGEO(生成エンジン最適化)に必要なのか?
従来のSEO(検索エンジン最適化)では、主にGooglebotのような検索エンジンのクローラーを意識した対策が中心でした。しかし、ChatGPTのような生成AIが台頭し、ユーザーが情報を得る手段としてAIによる要約や回答を利用する機会が増えています。これらのAIも、その知識ベースを構築・更新するためにウェブ上の情報をクロールしています。これが「GEO(生成エンジン最適化)」という新しい考え方で重要視される点です。
もし、あなたのウェブサイトがこれらのAIボットのアクセスをrobots.txtで拒否していた場合、AIはあなたのサイトの情報を学習できません。その結果、ユーザーがAIに関連する質問をした際に、あなたの専門知識や製品・サービスがAIの回答に含まれず、貴重な認知の機会を失う可能性があります。逆に、AIボットに適切に情報を収集してもらうことで、AIが生成する回答の中であなたのコンテンツが引用されたり、参照元として紹介されたりするチャンスが生まれます。これは、新しい形でのトラフィック獲得やブランド認知向上に繋がるため、GEO戦略においてAIボットへのアクセス許可は非常に重要です。
参考:robots.txt の概要 | Google Search Central
信頼できる主要なAIボットとアクセス許可のメリット
現在、様々な企業がAIモデルの開発と運用のためにウェブクロールを行っています。その中でも、自社サイトの情報を学習してもらうことでメリットが期待できる、信頼性の高い主要なAIボットがいくつか存在します。これらのボットからのアクセスを許可することで、あなたのウェブサイトのコンテンツがAIの知識に取り込まれ、より多くのユーザーの目に触れる機会が増えることが期待されます。
以下に、代表的なAIボットとそのユーザエージェント(ボットを識別するための名前)の例を挙げます。
| AIボット名 (提供元) | User-agent | 主な目的・許可するメリット |
|---|---|---|
| Google-Extended (Google) | Google-Extended | GoogleのVertex AIやBardなどの生成AIモデルの学習データ収集。許可することで、GoogleのAIサービスにおけるコンテンツの可視性が向上する可能性があります。 |
| GPTBot (OpenAI) | GPTBot | ChatGPTなどで利用されるOpenAIのAIモデルの学習データ収集。許可することで、OpenAIのAIモデルがあなたのサイト情報を学習し、関連性の高い回答を生成する際に役立つ可能性があります。 |
| ClaudeBot (Anthropic) | ClaudeBot | Anthropic社のAIモデル「Claude」の学習データ収集。幅広い分野での高品質な応答生成を目指しており、許可することで多様なAIユーザーへのリーチが期待できます。 |
| PerplexityBot (Perplexity AI) | PerplexityBot | AI検索エンジンPerplexity AIの学習データ収集。情報源を明示する形で回答を生成するため、引用されることによる直接的なトラフィック増加も期待できます。 |
| ChatGPT-User (OpenAI) | ChatGPT-User | ChatGPTのプラグインやGPTベースのアクションがウェブサイトにアクセスする際に使用されます。特定の機能を利用するユーザーからのアクセスを許可します。 |
これらのボットは、ウェブ全体の情報をより良く理解し、ユーザーに役立つ情報を提供するために活動しています。あなたのサイトが価値ある情報を提供しているならば、これらのボットにアクセスを許可することは、その価値をAIを通じて広めることに繋がります。
参考:
・Google クローラ(ユーザー エージェント)の概要 – Google-Extended
・GPTBot – OpenAI
・ClaudeBot – Anthropic
・PerplexityBot – Perplexity AI
robots.txtの具体的な記述方法:AIボットを許可する
それでは、実際にrobots.txtファイルにAIボットのアクセスを許可するための記述方法を見ていきましょう。記述は非常にシンプルです。特定のボット(ユーザーエージェント)を指定し、そのボットに対してアクセスを許可または禁止するルールを書きます。
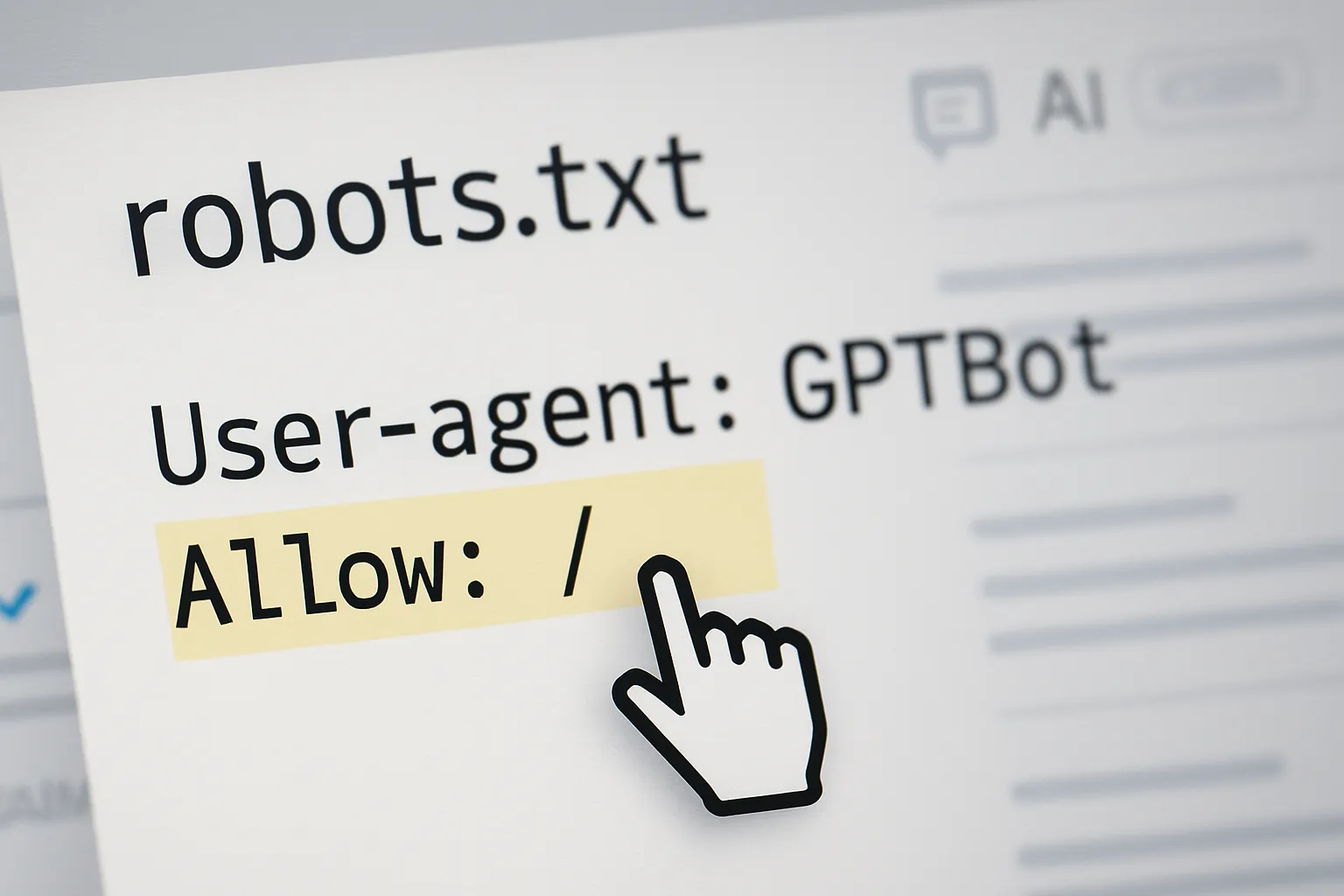
特定のAIボット(例:GPTBot)にサイト全体へのアクセスを許可する場合:
User-agent: GPTBot
Allow: /
この記述は、「GPTBotという名前のクローラーに対して、サイト内の全てのファイル・ディレクトリ(/でルートを表す)へのアクセスを許可(Allow)します」という意味になります。 多くのAIボットはデフォルトでアクセスを試みますので、特にアクセスを拒否する設定(Disallow)がなければ、明示的なAllowは不要な場合もありますが、意図を明確にするために記述することも有効です。
複数のAIボットにまとめてアクセスを許可する場合(個別に設定する方が確実です):
もし、特定のAIボット群にまとめて許可を与えたい場合、それぞれのUser-agentに対して設定を繰り返します。
User-agent: Google-Extended
Allow: /
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
注意点:
User-agent: *は「すべてのボット」を意味します。もし、User-agent: *の後にDisallow: /(サイト全体をブロック)と記述されている場合、個別のAIボットを許可するには、User-agent: *のブロック指定よりも前に、個別のボットに対する許可設定を記述するか、より具体的に許可する必要があります。しかし、基本的には個別のボットに対して明示的に許可/不許可を設定するのが推奨されます。- 記述ミス(例えば
Allowをalowと間違えるなど)は正しく解釈されないため、注意深く確認しましょう。 robots.txtは大文字・小文字を区別します(特にファイルパス)。
最もシンプルなのは、サイト全体へのアクセスを拒否するような包括的なDisallow: /設定がない限り、主要なAIボットに対して特に制限を設けないことです。AIボット側もrobots.txtの指示を尊重するように設計されているため、デフォルトでアクセスが許可されている状態を維持するのが一般的です。
注意!悪質なボットや不要なクローラーのブロックも忘れずに
信頼できるAIボットにアクセスを許可する一方で、全てのボットを無条件に歓迎するのは得策ではありません。世の中には、ウェブサイトのコンテンツを無断でコピーしようとする悪質なボットや、サーバーに不必要な負荷をかけるだけの迷惑なクローラーも存在します。これらを野放しにしておくと、サーバーリソースの浪費、セキュリティリスクの増大、さらにはコンテンツの不正利用といった問題を引き起こす可能性があります。
そのため、robots.txtを利用して、これらの望ましくないボットからのアクセスをブロックすることも重要です。特定の悪質と判断されるボットのUser-agentが判明している場合は、以下のように記述してアクセスを拒否できます。
User-agent: BadBotNameExample
Disallow: /
User-agent: AnotherUnwantedCrawler
Disallow: /
どのボットが悪質かを見極めるのは難しい場合もありますが、ウェブサイトのアクセスログを定期的に確認し、不審な挙動を示すUser-agentや、明らかに自サイトと関連のない情報を大量に収集しようとしているボットを見つけた場合は、ブロックを検討すると良いでしょう。重要なのは、有益なAIボットには道を開きつつ、不要または有害なトラフィックは遮断するというバランスです。これにより、ウェブサイトの健全性とパフォーマンスを維持しながら、AI時代に対応していくことができます。
robots.txt設定時のチェックポイントと注意点
robots.txtファイルを設定・変更する際には、意図した通りに機能しているか、また予期せぬアクセス制限をしていないかを確認することが非常に重要です。誤った設定は、検索エンジンからのインデックス登録を妨げたり、有益なAIボットのアクセスをブロックしてしまったりする可能性があるためです。
以下に、設定時や変更後に確認すべきチェックポイントと注意点をリスト形式でまとめました。
- ファイル名は正確か?: 必ず
robots.txtという小文字のファイル名で、サイトのルートディレクトリ直下に配置してください。 - 記述ルールは正しいか?:
User-agent:やAllow:、Disallow:といったディレクティブのスペルミス、コロンの有無、各行の記述順序などを確認しましょう。 - 構文エラーはないか?: Google Search Consoleの「robots.txtテスター」のようなツールを利用すると、構文エラーや意図しないブロックがないかを確認できます。
- 対象のボット名は正確か?: 許可またはブロックしたいボットの
User-agent名が正しく記述されているかを確認しましょう。大文字・小文字も区別される場合があります。 - パスの指定は正しいか?:
Allow: /やDisallow: /private/のように、パスの指定が意図通りか確認します。特に、サイト全体をブロックするDisallow: /が意図せず記述されていないか注意が必要です。 - UTF-8で保存されているか?:
robots.txtファイルはUTF-8でエンコードされていることが推奨されます。 - 設定変更後は反映に時間がかかる場合がある: 変更した
robots.txtの内容がクローラーに認識されるまで、少し時間がかかることがあります。 - 定期的な見直し: 新しいAIボットが登場したり、サイト構造が変更されたりした場合に備え、
robots.txtの内容を定期的に見直すことが望ましいです。
これらの点に注意してrobots.txtを管理することで、ウェブサイトと様々なボットとの良好な関係を築き、GEO戦略を効果的に進めることができます。
参考:robots.txt の仕様 | Google Search Central
まとめ:AI時代のウェブサイト運営とrobots.txtの賢い活用
この記事では、AI時代におけるrobots.txtの重要性と、信頼できるAIボットのアクセスを許可するための具体的な方法について解説しました。生成AIが情報提供の主要な手段の一つとなりつつある現代において、robots.txtは単なるクロール制御ファイルではなく、自社の情報をAIに届け、GEO(生成エンジン最適化)効果を高めるための戦略的なツールとしての意味合いを強めています。
robots.txt記述参考例:主要AIボットと一般的な検索エンジンボットへの対応】
以下は、一般的な検索エンジンボット(Googlebotなど)と、主要なAIボット(Google-Extended, GPTBot, ClaudeBot, PerplexityBot)へのアクセスを許可しつつ、特定のディレクトリ(例:/private-directory/や/temp-files/)へのアクセスは全てのボットに禁止する、より実践的な記述例です。
User-agent: Googlebot
Allow: /
Disallow: /private-directory/
Disallow: /temp-files/
User-agent: Google-Extended
Allow: /
Disallow: /private-directory/
Disallow: /temp-files/
User-agent: GPTBot
Allow: /
Disallow: /private-directory/
Disallow: /temp-files/
User-agent: ClaudeBot
Allow: /
Disallow: /private-directory/
Disallow: /temp-files/
User-agent: PerplexityBot
Allow: /
Disallow: /private-directory/
Disallow: /temp-files/
User-agent: *
Disallow: /private-directory/
Disallow: /temp-files/
# 上記以外の特定のディレクトリへのアクセスを全ボットに禁止する場合
# Disallow: /another-restricted-area/
Sitemap: https://www.example.com/sitemap.xml
この例では、個別のボットごとに許可・不許可を設定し、最後にUser-agent: *でその他全てのボットに対する共通の禁止ルール(この例では同じディレクトリ)を指定しています。また、サイトマップの場所を明示することで、クローラーがサイト構造を効率的に把握する手助けをします(ご自身のサイトマップURLに置き換えてください)。
重要なのは、OpenAIのGPTBotやGoogle-Extendedのような信頼できるAIボットに対しては積極的に情報収集の道を開き、同時に悪質なボットや不要なクローラーからはウェブサイトを保護するという、バランスの取れた設定を行うことです。robots.txtを適切に管理し、定期的に見直すことで、AIとの良好な関係を築き、新しい時代のビジネスチャンスを最大限に活用していきましょう。ぜひ、この機会にご自身のウェブサイトのrobots.txt設定を確認してみてください。



